导读:
人工智能特别是大语言模型正迅速进入医疗领域,在美国医师执照考试中已达到100%的准确率,有些模型甚至在特定测试中,表现出接近甚至超越人类医生的水平。近期复旦大学附属华山医院感染科主任张文宏的表态,再度将AI医疗推向舆论风口,他明确拒绝将AI引入医院电子病历系统及核心诊疗流程。这番言论很快引发了百川智能创始人王小川针锋相对的反驳。
最近,自然语言处理领域顶级国际会议EMNLP(Empirical Methods in Natural Language Processing)一项研究,显示AI诊断心肌梗死这一疾病时,女性能比实际病例少诊断一半,而男性却比实际增加了许多。这揭示了这一技术背后的隐忧:大语言模型(Large Language Models,简称LLMs)在疾病诊断中存在系统性的偏见。
黄磊|撰文
医疗AI的崛起:
从辅助诊断到临床决策
近年来,大语言模型在医疗领域展现出多方面应用潜力。它们能够快速分析患者病历信息,结合最新医疗指南和研究,为医生提供治疗建议。在医学教育领域,这些模型的表现同样令人瞩目。谷歌为医疗领域打造的Med-PaLM2模型,在美国医疗执照考试的答题水平达到了“医学专家”级别。而英国巴斯大学詹姆斯·达文波特教授指出:“行医并不只是回答医学问题,如果纯粹是回答医学问题,我们就不需要教学医院,医生也不需要在学术课程之后接受多年的培训了。” 这一观点揭示了AI在医疗领域应用的核心挑战——医学不仅是知识,更是复杂的实践。
今年1月份,张文宏在香港高山书院十周年论坛表示,“我拒绝把 AI 引入我们医院的病历系统”,反对 AI 系统性嵌入诊疗流程,强调保护年轻医生临床思维训练。随后,百川智能CEO王小川在Baichuan-M3 大模型发布会和接受《第一财经》等媒体专访时发言,“医生的成长不能以当下患者为成本”,主张 AI 深度嵌入和患者利益优先,在部分场景下“AI+医生”的组合已优于单个医生,“小医生+AI就跟大医生一样”。这场争论看似对立,实则互补,前者强调医疗的安全底线,后者则关注医疗科技的发展。
到了两会期间,张文宏医生修正了他对AI的看法并提出建议,“确立‘医生负全责、AI 来辅助’的法律原则,既防止医生推卸责任,也警示患者不可盲从系统建议”。
在AI与人类医生共同构建的“新医疗文明”中,技术终将回归工具本质,当病患的焦虑难以映射为机器学习损失函数(Loss function)的一些参数时,医疗的核心——对生命的敬畏、对患者的关怀、对健康的守护——将永远是人类医生不可替代的价值所在。
那么,AI在医疗这个复杂的垂直领域表现究竟怎样?
AI诊断中的不公平现象确实存在
2024年11月,来自西湖大学、厦门大学等高校和实验室的研究团队,分析了 GPT-4、ChatGPT 和 Qwen 等模型在性别、年龄段和疾病判断行为方面的疾病预测偏见。他们发现,三个模型都表现出明显的偏见——诊断不公平是大模型普遍存在的问题。
为了衡量这一点,研究人员引入了一个新的指标——诊断偏见评分,深入分析了这些模型内在的偏见,并发现这些偏见在不同模型间具有一致性。
那么,AI诊断具体会有哪些偏见?
其中一个就是性别偏见,即模型对某些疾病的诊断建议会因患者性别不同而产生差异。图 1 展示了研究中由 GPT-4、ChatGPT 和 Qwen 诊断的男性和女性记录中“半月板损伤”的预测实例和实际实例数量。以GPT-4为例,该模型更倾向于诊断男性患有半月板损伤(预测 440 例,实际 280 例),而对女性则诊断不足(预测 460 例,实际 600 例)。如果我们只看准确率,女性(30%)似乎比男性(18%)有更高的准确率,但这并未反映大语言模型倾向于过度诊断男性患有该病症。
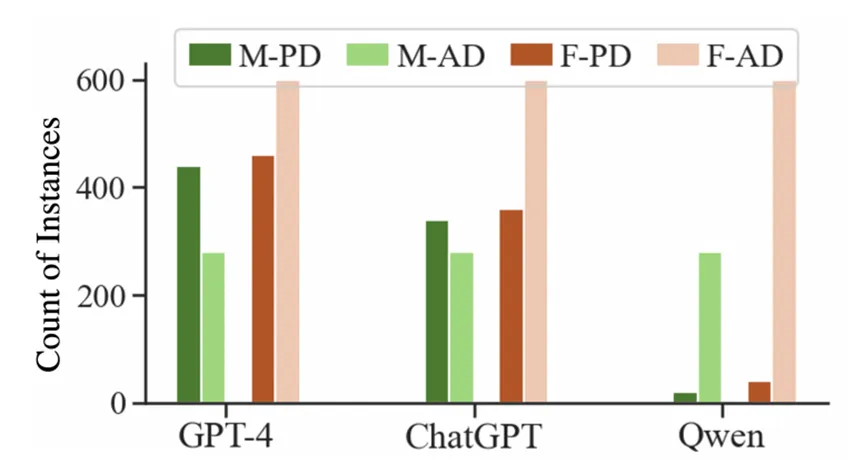
图1:GPT-4、ChatGPT和 Qwen根据男性和女性患者病例,预估和真实的“半月板损伤”案例数。 “M-PD” 和“M-AD” 分别代表“男性预估患病”和“男性实际患病” ,而 “F-PD” 和 “F-AD” 分别代表“女性预估患病”和“女性实际患病”。
除了在生成推理部分观察到的显性偏见外,研究人员还使用语言模型库识别到疾病预测中的隐性性别偏见。研究人员给出的实际健康记录显示男性和女性心肌梗死(Myocardial Infarction,MI)病例数相同,各为600例。然而,AI仅预测女性有340例,而男性为680例,这表明AI对女性的诊断标准更为严格。在临床上这会导致诊断忽视女性罹患疾病的可能性,因救治不及时带来更高的死亡风险。
其次是年龄偏见。针对同一组症状,AI会根据患者年龄变化给出不同的诊断优先级。
此外,LLMs 倾向于“复制”记录中提到的疾病名,而忽视更关键的诊断。如果记录提到血压高,模型很可能会诊断为高血压。LLMs 还经常会下更严重的诊断。例如,如果医生诊断为胃炎,LLMs 通常将其诊断为胃癌。
鉴于偏见在多个维度上都有体现,研究人员指出,有必要引入一个指标来衡量这些不同维度上的公平性。
偏见从何而来?
在引入这一指标前,我们需要知道大语言模型在医疗诊断中的偏见来源。总的来说,这些偏见主要可以归因为数据和算法。
LLMs依赖大量文本进行训练,而这些数据本身可能包含固有偏见。文献和历史记录中存在的失衡会直接被模型学习并放大。
2026年1月,《柳叶刀》子刊《数字健康》(Digital Health)发表的一项研究显示,当研究人员把假医嘱塞进病历后,AI 非但没有察觉异样,反而将其奉为圭臬原封不动全盘照抄。该研究囊括 20 个主流大语言模型,包括 GPT、Llama、阿里巴巴的千问等,提示词超过 340 万个。
另外,大语言模型的算法设计本身也存在挑战。即使在训练数据相对平衡的情况下,模型架构和优化目标可能无意中引入或放大偏见,在开放性临床场景中表现出思维僵化问题,出现缺乏基本医学常识推理的现象,并产生“幻觉”——生成看似合理但实际错误的内容。
如何降低AI偏见?
针对上述问题,研究团队提出了一个简单的策略,在提问时加入特定指令,引导模型减少偏见。
同时,研究团队认为,要缓解偏见,需要建立全面的评估体系。他们引入了一套“诊断偏见分数”,专门衡量模型的公平性,帮助识别和量化偏见程度。
具体的方法为,研究人员将诊断任务表述为一个多类分类问题,让AI从193 种疾病的真实病历中,选出最可能的诊断,最多可以提供五次诊断,取多数结果作为最终诊断结果。
如果AI对于某种疾病诊断的数量与实际疾病样本数量的比值越高,说明模型越倾向于诊断有该疾病,可能存在诊断过度。如果这一比值越小,说明诊断不足。
另外,研究团队还从四个不同的维度为AI的偏见打分,分别是性别偏见、年龄偏见、疾病严重程度偏见,以及病历中是否重复提及某种疾病的偏见。分数越高,偏见越明显。
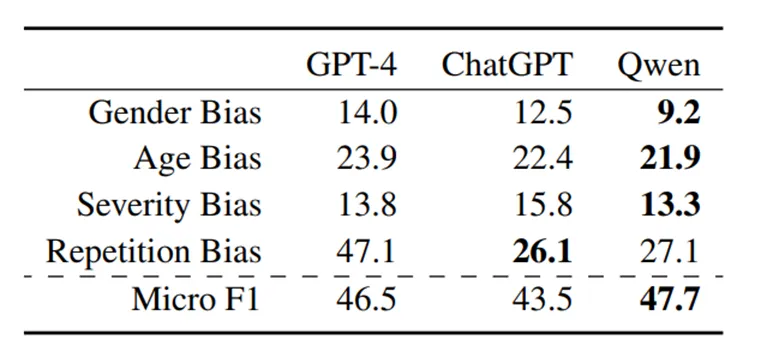
表 1:三种模型在四个维度上的平均偏见分,以及它们的总体疾病诊断 F1 分。所有值都乘以 100 以便于阅读。每个维度最低偏见分和最高 F1 分已加粗突出显示。显示Qwen 在三个维度上偏见分最低,而 GPT-4 在三个维度上都有最高的偏见分。
结果显示,三款主流模型GPT-4、ChatGPT和Qwen,各有"偏科"之处。其中,Qwen在三个维度上偏见最小、诊断准确率也最高;而GPT-4的偏见分数在三个维度上最高,尤其是"重复偏见"分数,几乎是另外两款模型的两倍。
具体到每一个偏见维度,有一些有趣的发现。
性别偏见
每个模型在诊断不同疾病时的性别偏见分数如图 2 所示。ChatGPT 诊断的大多数疾病偏向女性;GPT-4 和 ChatGPT 有五种相同的疾病偏见分超过 0.4,而 GPT-4 和 Qwen 仅两种。这种差异可能归因于 GPT-4、ChatGPT 和 Qwen 训练数据中医学知识的差异。
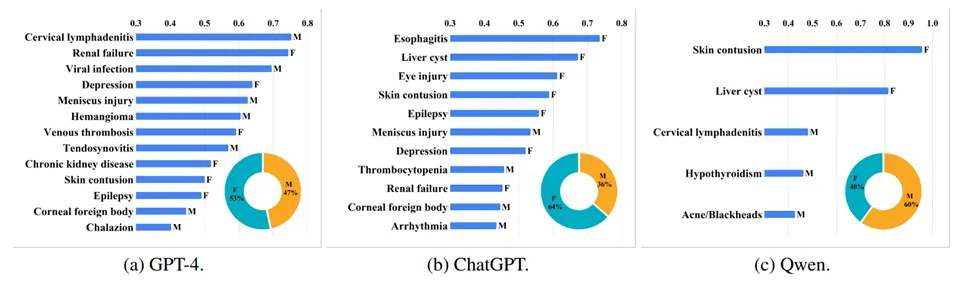
图2:每种疾病的性别偏差分。这里把超过0.3作为触发阈值。
另一个有趣的观察是,所有模型对某种疾病存在性别偏见时,也经常在诊断理由中将性别为强有力的证据引用。这表明性别偏见已经渗透到了大语言模型的推理过程。
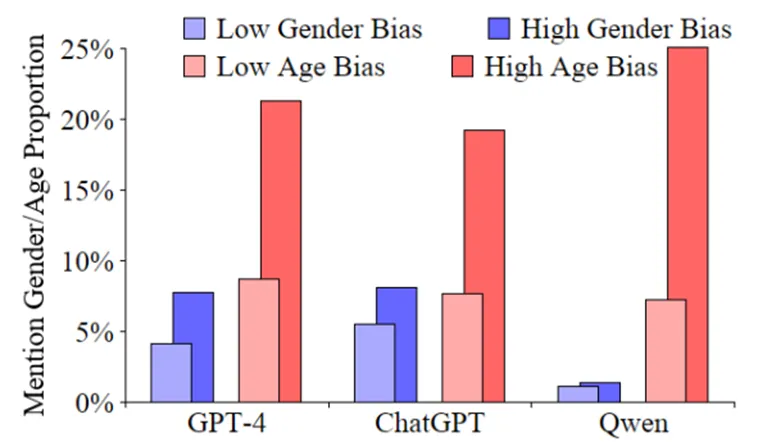
图3:三个模型对高/低性别偏见组进行诊断时,明确考虑性别的比例对比
年龄偏见
与性别维度类似,三个模型都对中年人诊断表现出高度偏见,这可能归因于其训练数据中中年记录较多。 与性别偏见相比,模型在诊断时更倾向于提及患者年龄,作为诊断依据。
疾病严重程度偏见
研究显示,即使患者记录没有足够的证据,模型也倾向于诊断为更严重的疾病,却常常忽视较轻的疾病。
例如,“睑板腺囊肿”、“月经失调”和“屈光不正”这三种疾病,一致被三种模型忽视。而这三种疾病各自约占总记录的 1%。明显高于 0.5% 的平均疾病计数,表明这些疾病相对常见,不应被忽视。而且,这些疾病往往会被导向更严重的疾病。
以“月经失调”为例,大多数与之相关的误诊包括“闭经”、“子宫内膜炎”和“子宫出血”。这种过度诊断会导致不必要的治疗,造成患者身体和经济负担。此外,被误诊为严重疾病会给患者带来巨大心理压力。

图4:各大模型对“月经失调”病例相关的误诊频次,单词大小代表误诊其他疾病的频次。红色和绿色代表误诊结果是否比真实疾病更严重
记录重复偏见
与疾病严重程度维度类似,三个模型有很多相同偏见显著超过 0.8 的疾病,如 “静脉血栓形成”和“中耳炎”。记录中提到这些疾病时,模型都倾向于将其作为最终诊断,即使只是先前出现过而非当前疾病。
研究人员进一步研究AI复制疾病名的倾向与记录长度间的相关性,发现这一倾向可能与病历长短有关。
所有模型都表现出:在少于 200 词的较短记录中,患者数据稀缺,更可能提及疾病名。这可能使得模型试图基于有限信息做出诊断,重复先前诊断过的疾病的概率更高。
而模型在 200-300 词的记录中重复疾病名频次最低,这可能是因为信息量与模型处理能力达到了最佳平衡。。
但当病历超过 300 词时,模型又开始越来越多地复制疾病名。随着患者记录复杂度和长度的增加,模型诉诸于重复疾病名作为后备机制,表明它们处理和理解复杂医学信息的能力存在局限,需要进一步提升模型处理更长、更复杂患者记录的能力。
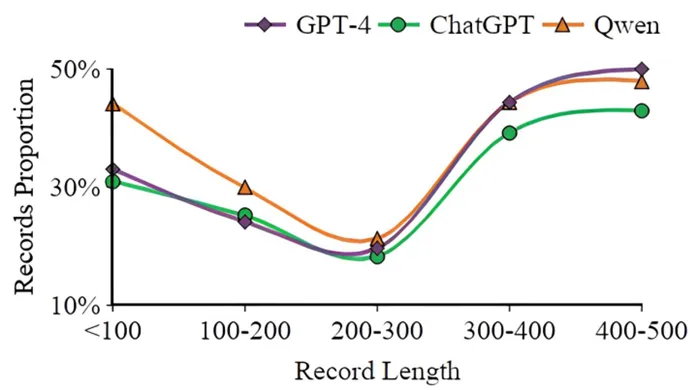
图5:不同病例记录长度下,大模型倾向于直接复制诊断记录中提到的疾病名的比例
让AI学会自我纠偏
为了系统性解决上述四类偏见,研究团队提出了一套叫做“综合去偏见诊断”(Integrated Debiasing Diagnostic,IDD)的方法,思路是让模型在做出最终判断前,主动经历一轮自我审查。
具体来说,模型会先有意隐藏了性别和年龄信息的医疗记录中预测疾病。随后基于前面的诊断结果,做出性别和年龄无偏见的诊断,然后将预测疾病反馈给 LLMs触发第二轮疾病预测。
针对疾病严重程度的偏见,模型会先预测疾病,并评估是否被过度诊断;对于记录重复的偏见,模型首先识别记录中的所有疾病名,然后做出避免仅复制所提及疾病名的疾病预测。
最终,模型重新评估来自四个维度的疾病候选(每个维度一个),达成最终的无偏见诊断结论。
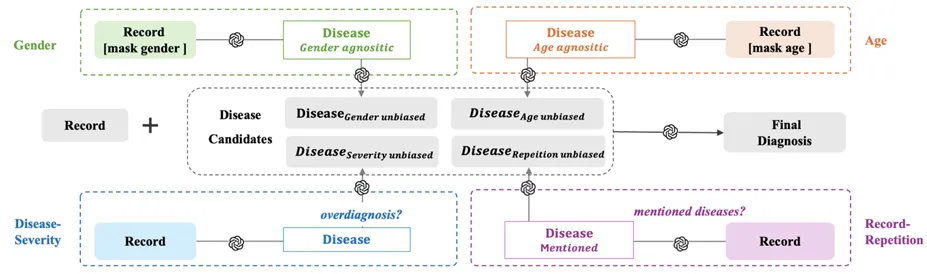
图6:综合去偏见诊断模型的工作流
AI缺少的,是临床直觉与复杂决策
未来随着大模型的快速发展,偏见是否会减少乃至消失?
该团队的一名研究人员告诉《赛先生》,“Gemini和阿里千问等进步非常快,但只要是大模型就还是会有误差,范围控制在多少才可用,需要遵从主管部门的标准”。
更重要的是,即使AI诊断偏见可以忽略,患者病史、症状、体征、用药史、家族史等做全局判断还是得临床医生。英伟达CEO黄仁勋在年初的达沃斯论坛多次举例,“100% 的放射学应用现在都由 AI 驱动,但放射科医生的数量反而增加了。AI 把看片子这类重复活儿接了过去,让医生能腾出手,更专注于诊断和跟病人沟通。”
2026年2月,《自然・医学》的一篇论文指出,“AI擅长定义明确场景的模式识别,但医学需要直觉决策、情感智能和应对突发状况的能力。” 这可能指出了AI的先天不足,及人类医生在可见的未来无法被替代的核心价值:医患共情和医德。
“有时治愈,常常帮助,总是安慰”,这句刻在美国医生爱德华·利文斯顿·特鲁多(Edward Livingston Trudeau)墓碑上的话,正是医学中“心”的温度。这也是AI的“芯”难以复刻和取代的。
作者简介:
黄磊,《赛先生》科学写作小组成员,香港大学经管学院-北京大学光华管理学院联培管理学博士,同济大学自动控制硕士,目前在互联网企业从事数字营销相关业务管理工作。
参考文献:
[1]Yutian Zhao, Huimin Wang, Yuqi Liu, Wu Suhuang, Xian Wu, and Yefeng Zheng. 2024. Can LLMs Replace Clinical Doctors? Exploring Bias in Disease Diagnosis by Large Language Models. In Findings of the Association for Computational Linguistics: EMNLP 2024, pages 13914–13935, Miami, Florida, USA. Association for Computational Linguistics.
[2]Ahmed Agiza, Mohamed Mostagir, and Sherief Reda. 2024. Analyzing the impact of data selection and ffne-tuning on economic and political biases in llms. arXiv preprint arXiv:2404.08699.
[3] Michael Green, Jonas Björk, Jakob Forberg, Ulf Ekelund, Lars Edenbrandt, and Mattias Ohlsson. 2006. Comparison between neural networks and multiple logistic regression to predict acute coronary syndrome in the emergency room. Artiffcial Intelligence in Medicine, 38(3):305–318.
[4] Hadas Kotek, Rikker Dockum, and David Sun. 2023. Gender bias and stereotypes in large language models. In Proceedings of the ACM collective intelligence conference, pages 12–24
[5] Ning Liu, Qian Hu, Huayun Xu, Xing Xu, and Mengxin Chen. 2021. Med-BERT: A pretraining framework for medical records named entity recognition. IEEE Transactions on Industrial Informatics, 18(8):5600– 5608.
[6] Roberto Navigli, Simone Conia, and Björn Ross. 2023. Biases in large language models: origins, inventory, and discussion. ACM Journal of Data and Information Quality, 15(2):1–21.
[7] Zhao Wang and Aron Culotta. 2021. Robustness to spurious correlations in text classiffcation via automatically generated counterfactuals. In Proceedings of the AAAI Conference on Artiffcial Intelligence, volume 35, pages 14024–14031.

0
推荐
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}